Someone on your team edited the system prompt of your customer support AI.
They changed "respond in a professional but friendly tone" to "respond professionally." Seems minor. But your AI now sounds like a legal document to customers who used to get warm, helpful responses.
Nobody noticed for three weeks. You found out when support tickets started mentioning "the bot sounds different."
This is the production incident that LLMOps exists to prevent.
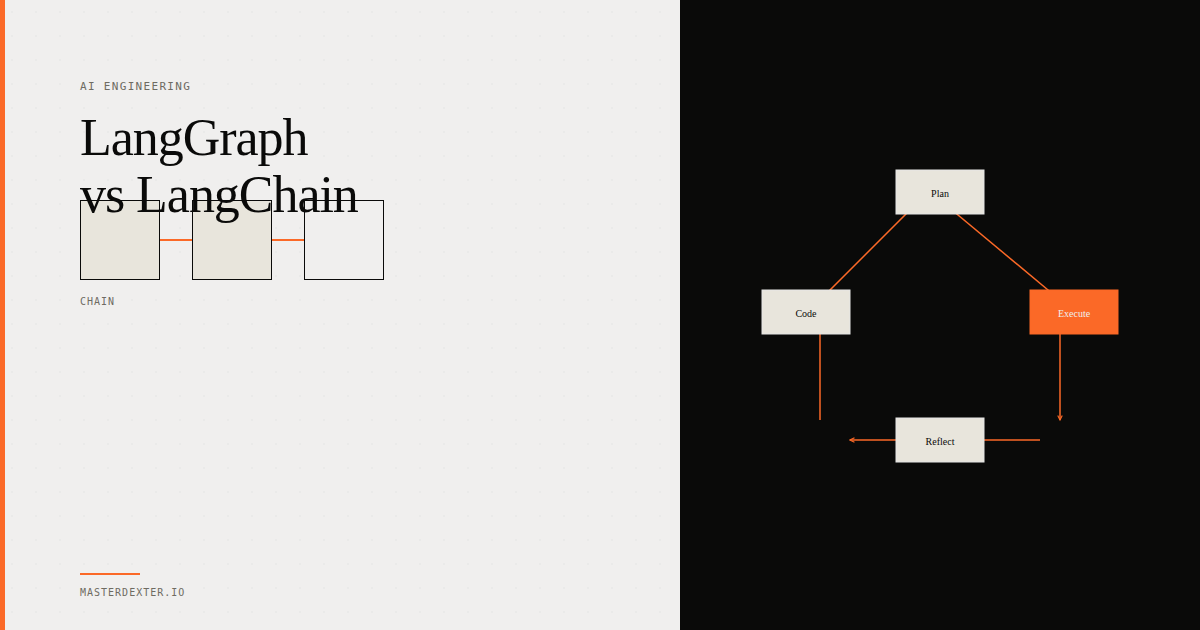
What LLMOps is (and why it is different from MLOps)
Traditional MLOps tracks three things: data, model, and code. Change any of them, you may need to retrain and redeploy.
LLMOps has all of that plus two new moving parts: prompts and model versions.
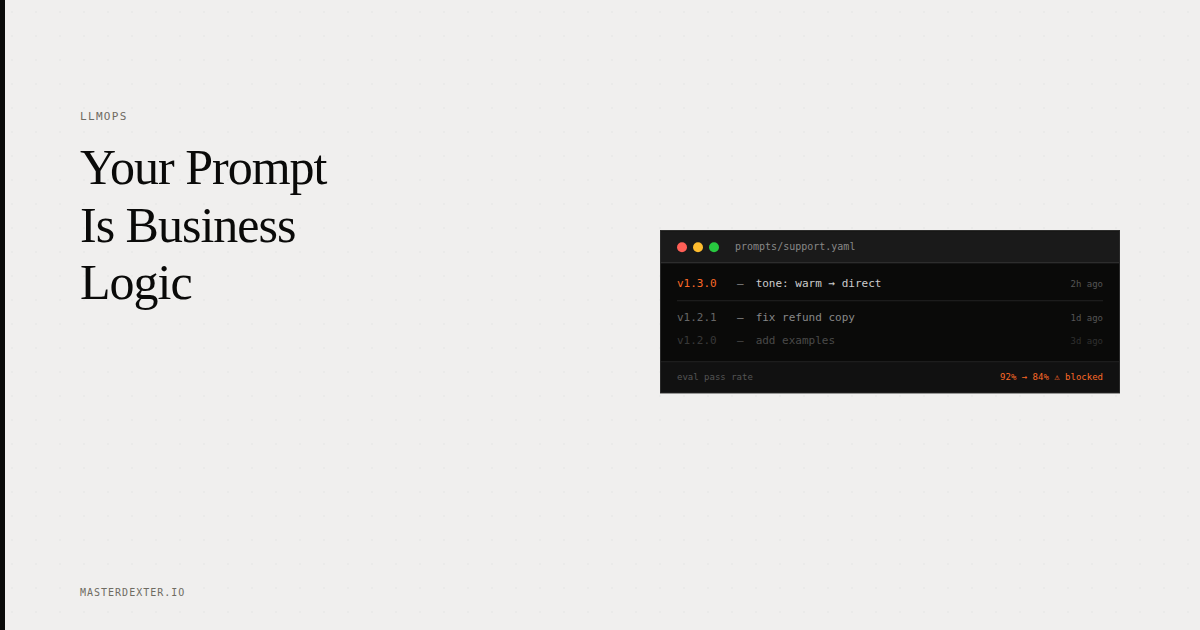
A prompt is effectively business logic. If someone edits the system prompt of your customer support AI, they may have just changed how your product behaves for thousands of users. That change should go through version control the same way a code change does.
Model versions matter because your API provider updates their models. GPT-4-turbo is not GPT-4o. Claude 3 Opus is not Claude 3.5 Sonnet. When a new model version drops, your evals should run automatically to confirm your prompts still perform as expected before you switch.
Prompt versioning: how to do it
The implementation is simpler than most teams expect. Store prompts in YAML or JSON files in your Git repository. Your deployment pipeline reads from those files. Every prompt change goes through pull request review the same way every code change does.
# prompts/customer_support_v1.2.0.yaml
version: "1.2.0"
updated: "2026-06-10"
updated_by: "connect@himanshuramchandani.co"
changelog: "Added specific language for refund queries. Removed formal tone instruction."
system: |
You are a customer support specialist for [Company Name].
Your tone is warm, direct, and helpful.
Always acknowledge the customer's situation before providing a solution.
If you cannot resolve the issue, escalate with a specific next step and timeframe.
examples:
- user: "My order hasn't arrived after 10 days."
ideal: "That is frustrating and I understand. Let me pull up your order right now..."
test_cases:
- input: "Can I get a refund?"
expected_behavior: "Acknowledges request, explains policy clearly, gives specific next step"
must_not_contain: ["unfortunately", "I'm afraid", "regret to inform"]
Semantic versioning applies: major version for behavior changes, minor for refinements, patch for typo fixes.
Every PR that modifies a prompt file triggers an automated eval run. If the eval pass rate drops below your threshold (typically 85%), the PR cannot merge. The same way a code change that breaks unit tests cannot merge.
Building the CI/CD pipeline for AI
The LLMOps pipeline mirrors DevOps but adds AI-specific steps:
Code commit → CI pipeline triggers
→ Unit tests (code)
→ Prompt regression tests (does the AI still answer correctly?)
→ RAG eval suite (is retrieval still accurate?)
→ Model comparison (new model vs current model on benchmark set)
→ If all pass: merge and trigger CD pipeline
CD pipeline → Deploy updated prompts to staging
→ Run smoke tests with live traffic sample
→ Canary deploy to 5% of production traffic
→ Monitor for quality degradation
→ Gradual rollout to 100%
The evaluation step is what makes this different from standard CI/CD. You need a set of "golden queries" - real-world questions with expected answers - that you run against every change.
Building your eval suite
Start with 50 to 100 golden queries per major use case. Each one needs:
- Input (the user query)
- Expected output or criteria (correct answer, required facts, or behavioral constraints)
- Evaluation method (exact match, LLM-as-judge, or semantic similarity)
LLM-as-judge is now standard practice. You use a capable model to score outputs on dimensions like faithfulness to source documents, relevance to the query, and tone compliance. It is not perfect, but it scales. A human reviewer might catch a few things the judge misses, which is why you keep humans in the loop for the most sensitive use cases.
Here is a minimal eval runner:
import pytest
from your_app.llm import run_prompt
GOLDEN_QUERIES = [
{
"input": "What is your refund policy?",
"must_contain": ["30 days", "receipt"],
"must_not_contain": ["unfortunately", "cannot"],
"tone_check": "warm"
},
# ... 49 more
]
@pytest.mark.parametrize("query", GOLDEN_QUERIES)
def test_prompt_regression(query):
response = run_prompt(query["input"])
for term in query["must_contain"]:
assert term.lower() in response.lower(), f"Missing required term: {term}"
for term in query["must_not_contain"]:
assert term.lower() not in response.lower(), f"Found forbidden term: {term}"
This takes a week to build. It saves you from shipping a broken update.
Monitoring what actually matters
Most teams monitor system metrics: latency, error rates, uptime. That is necessary but not sufficient for AI.
You also need to monitor:
Output quality over time. Run your golden queries on a weekly schedule. If your pass rate drops from 92% to 84%, something changed. Maybe the model, maybe your data, maybe something upstream.
Retrieval quality. Track how often retrieved documents are actually relevant to the query. A drop in retrieval relevance often precedes a drop in answer quality. Catching it early means you fix the ingestion pipeline before users notice.
User feedback signals. Thumbs down buttons, session abandonment, escalations to human agents. These are weak signals individually but meaningful in aggregate. Build a pipeline to collect and review them weekly.
Prompt injection attempts. In 2026, this is table stakes. Log queries that contain unusual instruction patterns and flag them for review.
The most common LLMOps failure
A vendor updates their model version. Your evals were not running automatically. You switched to the new model. Behavior changed. You found out from users.
This is why vendor change management is part of LLMOps. Every model provider updates their models. The safeguards are:
- A named technical owner inside your organization is responsible for monitoring each vendor's model change communications
- Model version is pinned explicitly in your configuration (never
model=latest) - Every model version switch triggers a full eval run before traffic moves
The pinning rule alone prevents most incidents. model=gpt-4o is a known thing. model=gpt-4o-latest is a variable that changes under you.
What a mature LLMOps setup looks like
After six months of building this properly:
- Every prompt change goes through PR review with an automated eval gate
- The eval suite covers 100+ golden queries across all major use cases
- Prompt version history is in Git with semantic versioning and changelogs
- Model version is pinned and monitored for deprecation notices
- Weekly eval reports show pass rate trends over time
- Production sampling reviews 2% to 5% of real queries weekly
- Any drop in pass rate triggers an alert before users notice
This is not complicated engineering. It is disciplined engineering applied to a new kind of artifact (prompts) that most teams still treat informally.
Your prompt is business logic. Treat it that way.
Want to build production AI systems with proper LLMOps?
In AI Engineer HQ, every artifact is deployed with CI/CD, observability via LangFuse, and prompt versioning. You leave with a working pipeline, not just code that runs on your laptop.
What I build and how I can help
- MasterDexter live cohorts
- MasterDexter Teams - private cohorts to train your AI team on production systems
- AITalentStudio - vetted, production-ready AI talent for your company
- Dextar - AI engineering development and consulting for enterprises and startups
- Buildership - ideas to ship real AI