A company came to me last year with a problem.
Their GPT-4 integration was generating customer emails that did not match their brand voice. Too formal. Wrong tone. Responses that sounded like a legal memo instead of a friendly SaaS company.
Their plan: fine-tune the model.
The actual fix: rewrite the system prompt in 45 minutes.
The revised prompt included three examples of their ideal email tone, explicit instructions about what to avoid, and a persona description. The model started producing on-brand responses immediately. No training run. No dataset. No GPU time.
This happens constantly. Fine-tuning is the expensive solution to problems that are usually a prompt engineering problem in disguise.
But sometimes fine-tuning is exactly the right answer. Here is how to tell the difference.
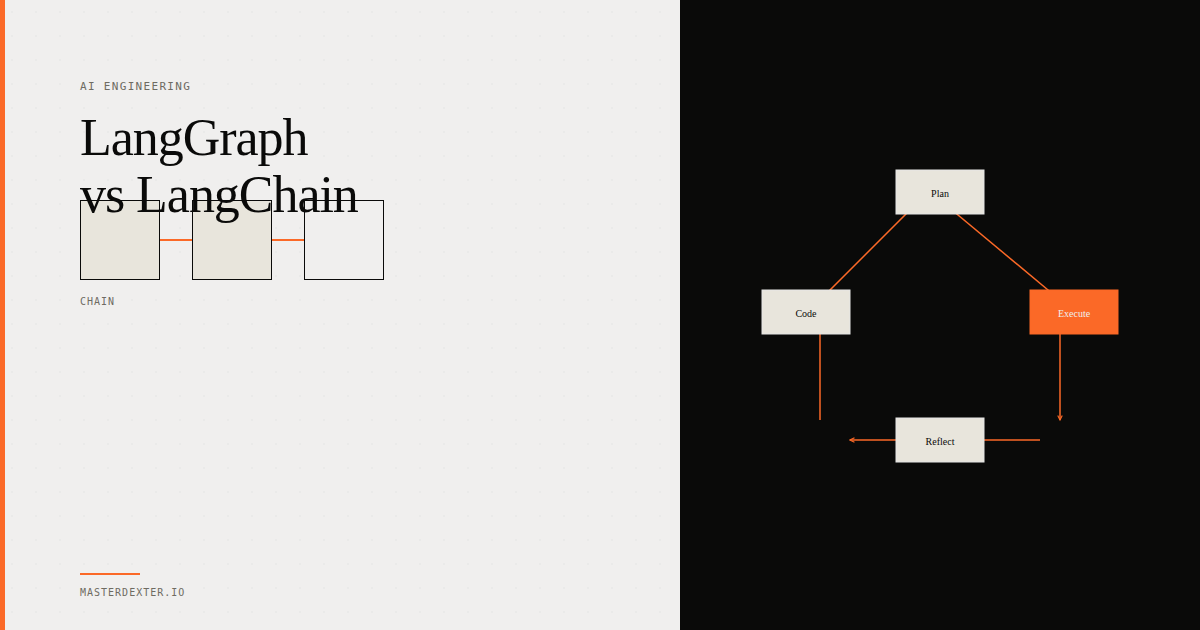
The decision starts with understanding what fine-tuning actually does
A general-purpose model like Claude or GPT-4 is optimized across thousands of tasks. Fine-tuning takes that general capability and adjusts the model's weights to perform better on a specific, narrow task.
The key insight: fine-tuning does not add new knowledge to the model. It adjusts behavior. It teaches the model to respond in a particular style, follow a specific format reliably, or prioritize certain patterns when reasoning.
This distinction determines when it is worth doing.
When to write a better prompt first
Almost always, the first step should be prompt improvement. Before you consider fine-tuning, ask:
Have you written a proper system prompt?
A system prompt that describes the role, the constraints, the output format, and the audience can fix 80% of quality problems. If your system prompt is one sentence, the model is being asked to guess your requirements.
Have you included examples?
Few-shot examples in the prompt are extraordinarily powerful. Three well-chosen examples of ideal output often produce results that match the quality of a fine-tuned model, with zero training cost.
Have you specified the output format explicitly?
If your model is giving you inconsistent JSON, inconsistent tone, or inconsistent structure, explicit format requirements and a schema in the prompt usually fix this.
Have you tried chain-of-thought prompting?
For reasoning tasks, asking the model to think step-by-step before producing output dramatically improves accuracy and consistency.
If you have done all four of these and still have persistent quality problems, then consider fine-tuning.
When fine-tuning is genuinely the right call
There are three situations where fine-tuning produces results that prompting cannot match.
Situation 1: Consistent format on a specific, narrow task at high volume.
You are processing 100,000 insurance claims per day and extracting a specific set of structured fields. The output format is always the same. The task is always the same. You cannot afford the latency or cost of sending 3-shot examples with every request.
A fine-tuned 8B model on this specific task, trained on 5,000 to 10,000 examples, will outperform a general-purpose model on cost (by roughly 10x), latency (by 5x), and consistency (dramatically). This is the Model Smith use case.
Situation 2: Domain-specific vocabulary and reasoning that is not in training data.
Your company has 15 years of proprietary clinical notes written in a specialized format. The abbreviations, terminology, and clinical reasoning patterns are specific to your institution. A general model has never seen this pattern.
Fine-tuning on your annotated historical data teaches the model your specific clinical vocabulary and reasoning style. Prompting alone cannot replicate this because the model does not have the pattern in its weights.
Situation 3: Consistent persona or voice across millions of interactions.
You have a customer-facing AI that needs to respond in a very specific brand voice across 10 million annual interactions. The cost of including extensive persona examples in every prompt becomes meaningful at that scale. A fine-tuned model that has internalized the voice requires a much smaller system prompt.
The cost comparison
Here is what makes this decision concrete:
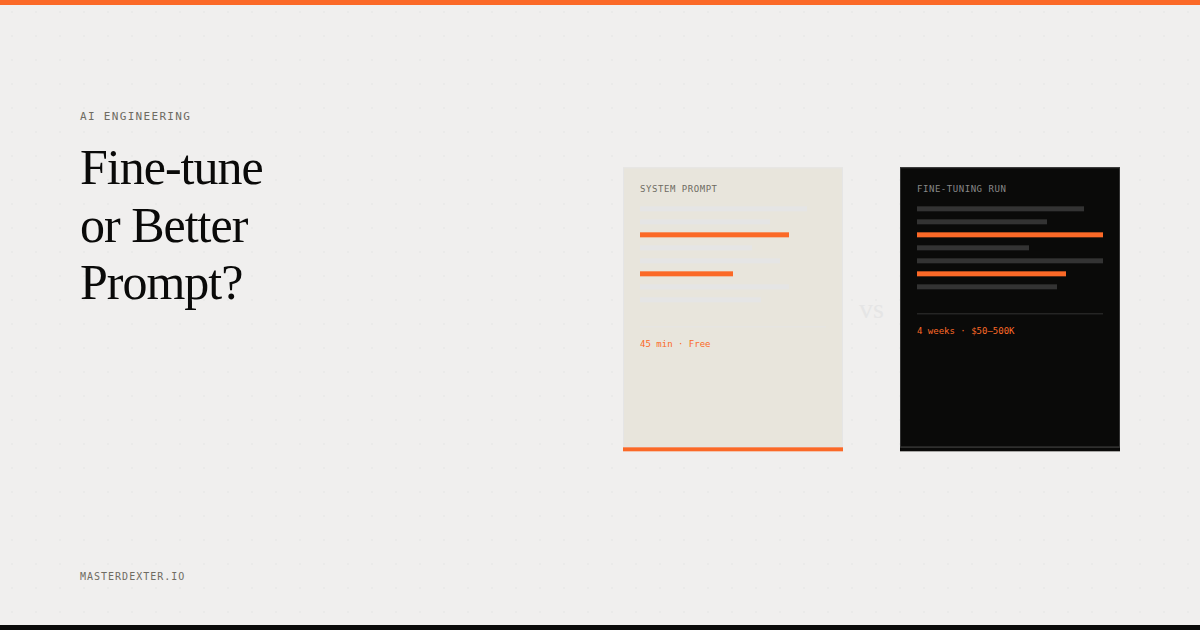
Prompt engineering cost:
- Engineering time: 1 to 5 days
- Infrastructure cost: zero
- Per-query cost: slightly higher (longer prompts)
- Time to result: days
Fine-tuning cost:
- Dataset creation: 2 to 8 weeks (this is usually the bottleneck)
- Training run (using QLoRA via Unsloth on RunPod): $1 to $10 for an 8B model
- Per-query cost: lower for high-volume tasks
- Time to result: weeks to months
The training run itself is cheap in 2026. The dataset creation is not. Cleaning, labeling, and quality-reviewing 5,000 training examples takes real time from real people with domain expertise. That cost is what most teams underestimate.
The synthetic data path
One pattern that changes the economics significantly: using a frontier model (GPT-5, Claude 4) to generate training data for a smaller model.
You start with 50 manually curated "golden examples" of the target task. You use an Evol-Instruct pipeline to evolve those 50 examples into 5,000 to 10,000 high-complexity training examples. You clean, deduplicate, and quality-filter that dataset. Then you fine-tune your 8B student model on it.
The result is a model that costs less than $0.10 per million tokens to run (versus $5 to $30 for a flagship model), answers in real time, and outperforms the general model on its designated task because it has seen thousands of task-specific examples.
The benchmark from a medical coding deployment: a fine-tuned Llama 3.2 8B model on ICD-10 code extraction matched GPT-4 accuracy at 1/100th of the inference cost.
But you still spent 4 to 8 weeks building the dataset. That cost is real and should not be skipped in your ROI calculation.
The one question that makes the decision
"Will this problem still exist if I write a much better prompt first?"
If the answer is yes, then fine-tune.
If you have not written a genuinely thorough prompt yet, that is where to start.
The ICD-10 extraction case was a genuine fine-tuning use case: 100,000 daily documents, specific structured output, cost pressure at scale. The brand voice case was a prompt engineering case: one system prompt with examples fixed it immediately.
The technology is the same. The problem determines which approach to use.
What I use in the cohort
In AI Engineer HQ, the fine-tuning artifact (Model Smith) is explicitly designed for situations where the economics justify it: narrow task, high volume, structured output, cost pressure.
Before anyone builds a fine-tuned model, they define the specific metric they are trying to improve, estimate the volume that justifies training cost, and evaluate whether a better prompt would solve the problem. That filter catches most fine-tuning plans that are actually prompt engineering problems.
The models that make it through that filter ship faster and perform better because the team understood the actual problem before they started.
Want to build fine-tuning pipelines that actually justify the investment?
In AI Engineer HQ, we build the full Model Smith pipeline: synthetic data generation, QLoRA fine-tuning, LLM-as-a-Judge evaluation, and deployment. You leave with a working deployed model and the framework to decide when to fine-tune versus when to write a better prompt.
What I build and how I can help
- MasterDexter live cohorts
- MasterDexter Teams - private cohorts to train your AI team on production systems
- AITalentStudio - vetted, production-ready AI talent for your company
- Dextar - AI engineering development and consulting for enterprises and startups
- Buildership - ideas to ship real AI