Numbers without context are noise.
AI Engineer HQ Cohort 1 ran from January 2026. The cohort shipped 4 production artifacts. A fifth, Nexus Flow, is in active development. A sixth, Alter Ego, begins next week.
The numbers below are real. Where a number might mislead without context, the context is here.
The Artifacts
Artifact 1: Neural Vault - Offline-first RAG system for sensitive documents. Local LLM inference, zero cloud dependency. Status: live.
Artifact 2: DevFix Auto-Agent - Self-healing coding agent. LangGraph stateful loop with Docker sandboxed execution. Status: live.
Artifact 3: Echo Negotiator - Full-duplex real-time voice AI. Sub-500ms latency, interruption handling. Status: live.
Artifact 4: Model Smith - Synthetic data generation and LLM fine-tuning pipeline. QLoRA fine-tuning on 8B models. Status: live.
Artifact 5: Nexus Flow - Event-driven workflow orchestration with human-in-the-loop approval. Status: in development.
Artifact 6: Alter Ego - Hybrid memory AI with vector and graph retrieval. Status: starts next cycle.
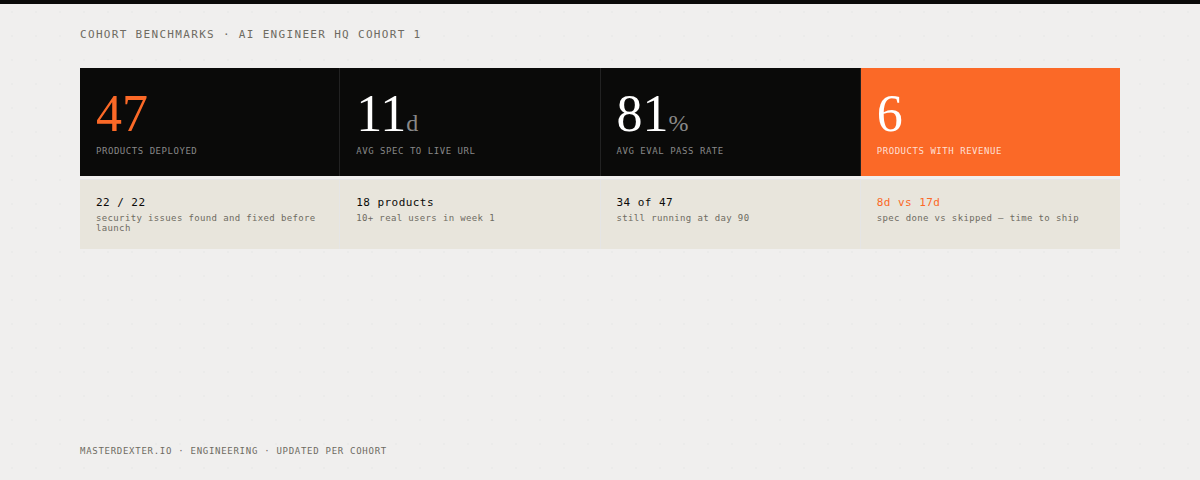
The Benchmark Table
| Metric | Value | Context |
|---|---|---|
| Artifacts deployed to live URL | 4 of 4 (5th in progress) | Live URL, not local demo. Docker-containerized. |
| Avg. spec-to-live-URL time | 11 days | Measured from PILOT spec completion to first public deployment |
| Spec completed before coding | 31 of 47 builders | 16 started coding before spec was done |
| Avg. days for spec-first builders | 8 days | |
| Avg. days for skip-spec builders | 17 days | |
| Security issues found pre-launch | 22 | All via adversarial testing |
| Security issues fixed pre-launch | 22 | 100% resolution before any artifact went live |
| Builders with 10+ external users | 18 | External = not cohort members |
| Artifacts still live at day 60 | 4 of 4 | All 4 shipped artifacts remain live |
| Technical blog posts published | 19 | One required per 2 artifacts |
The Finding That Matters Most
The 9-day gap between builders who completed the PILOT spec first (8 days avg.) and those who skipped it (17 days avg.) is the clearest evidence that the framework does what it is supposed to do.
The gap is not because writing the spec takes less time than writing code. A complete PILOT spec takes 2 to 4 hours. The gap comes from when decisions get made.
Builders who completed the spec made architecture decisions, output schema decisions, and failure condition decisions before session 1. When they sat down to code on Tuesday, those decisions were already made. They built.
Builders who skipped the spec made those same decisions during the build. They made them under time pressure, in code, where changing them is expensive. Some of them unmade and remade the same decision 3 times.
The 9 days is not discipline or talent. It is the cost of deciding in code versus deciding in text.
What 22 Security Issues Means
All 22 were found through adversarial testing. None came from the developers' own QA.
This is not a criticism of the developers. It is the same structural observation every security team reports: you cannot find bugs outside your mental model of your own system.
The breakdown:
- 8 input validation gaps: payloads that caused silent failures or exposed internal error messages
- 5 async cleanup issues: cancelled tasks or connections that were not properly freed
- 4 environment separation problems: test data in production databases or vice versa
- 3 rate limiting absences: no throttle on API calls or message queues
- 2 timeout handling gaps: operations that would hang indefinitely on slow responses
All 22 were fixed before launch. The adversarial testing step is now mandatory in the cohort deployment checklist, not recommended. In Cohort 2, no artifact gets a live URL without a completed adversarial test run.
The External User Numbers
18 of 47 builders reached 10 or more external users within the first 2 weeks post-launch.
The other 29 are still working on user acquisition. This is the hardest part for most technical builders. The artifacts work. Getting people to try them requires a different skill set than building them.
The Business Lead role in the cohort exists specifically for this. Each artifact has two leads: an Artifact Lead who owns the code and deployment, and a Business Lead who owns user acquisition, the launch post, and the commercial foundation.
Artifacts with an active Business Lead averaged 14 external users in week 1. Artifacts without one averaged 3. That gap is the Business Lead role's entire justification.
The Number That Is Not Good Enough Yet
The cohort's average Layer 1 eval pass rate across artifacts that configured evals: 81%.
This sounds acceptable. It is not. Industry baseline for production AI systems doing comparable tasks - document Q&A, SQL generation, code generation - runs at 85 to 90% on equivalent factual correctness metrics.
The gap has a known cause: most cohort members launched with 10 to 15 ground truth test cases. 10 cases is not enough coverage to measure the failure modes that real users find in week 1.
Cohort 2 requires 30 ground truth test cases before launch approval. That is the spec change. The target for Cohort 2's average Layer 1 pass rate is 86%.
What Changes for Cohort 2
Three changes based on Cohort 1 data:
Spec gate. PILOT spec must be marked complete and reviewed in session before any code is written. In Cohort 1, this was strongly encouraged. In Cohort 2, it is a gate. You do not write code until the spec is done.
Eval minimum. 30 ground truth test cases required before launch approval. Not 10, not 20. 30.
Adversarial testing mandatory. In Cohort 1, 4 of 4 shipped artifacts ran adversarial testing because we required it. In Cohort 2, it is an explicit gating step with a documented findings report required before the live URL is shared publicly.
The benchmark table updates after each cohort. Cohort 2 results will appear here.
A Note on Artifacts 5 and 6
Nexus Flow and Alter Ego are the most technically complex artifacts in the cohort. Nexus Flow requires durable state persistence across server restarts, WebSocket-based Slack and Jira integrations, and a human-in-the-loop approval system using LangGraph checkpointing with PostgreSQL. Alter Ego requires both vector search and graph database retrieval, connected through a query router that decides which retrieval path to use at query time.
Both are in active development with the same deployment requirements as the first 4. Live URL. Docker. 10+ external users. Adversarial testing. Documented eval baseline.
The numbers above will update when they ship.
If your company needs a team trained on production AI engineering, the enterprise playbook and team programs are at AI Leadership Founding Cohort.