Engineers do not need a list of impressive repos. They need to know what to read when they open one.
These 5 repos are from AI Engineer HQ Cohort 1. Each one has one specific file or commit worth your time. Everything else is context. What is listed below is the part that teaches something.
1. Neural Vault: Read the Chunking Module's Commit History
Repo: github.com/MasterDexterAI/neural-vault
What to look at: /src/document_processor.py - then read the full git log for that file with git log --follow -p src/document_processor.py.
The chunking strategy changed 3 times during Cohort 1. Version 1 used a flat 512-character window with no overlap. Version 2 moved to 1000 characters with 200-character overlap after retrieval quality dropped on multi-page documents. Version 3 added a strip and cleanup pass that removes noise characters that pypdf introduces when parsing tables.
The diff between version 2 and version 3 is 23 lines. Those 23 lines are the difference between a RAG system that correctly answers questions about documents with embedded tables and one that returns chunks full of \xa0\x0c\t artifacts that confuse the embedding model.
Read the commit messages in order. The reasoning is documented. The Artifact Lead wrote what they tried, what broke, and what the fix changed. That is rarer than it should be.
2. DevFix: Read Pull Request #47
Repo: github.com/MasterDexterAI/devfix-auto-agent
What to look at: Pull Request #47 on the governance branch.
An early version of the executor node had 2 input validation checks. A reviewer added 14 more before approving the PR.
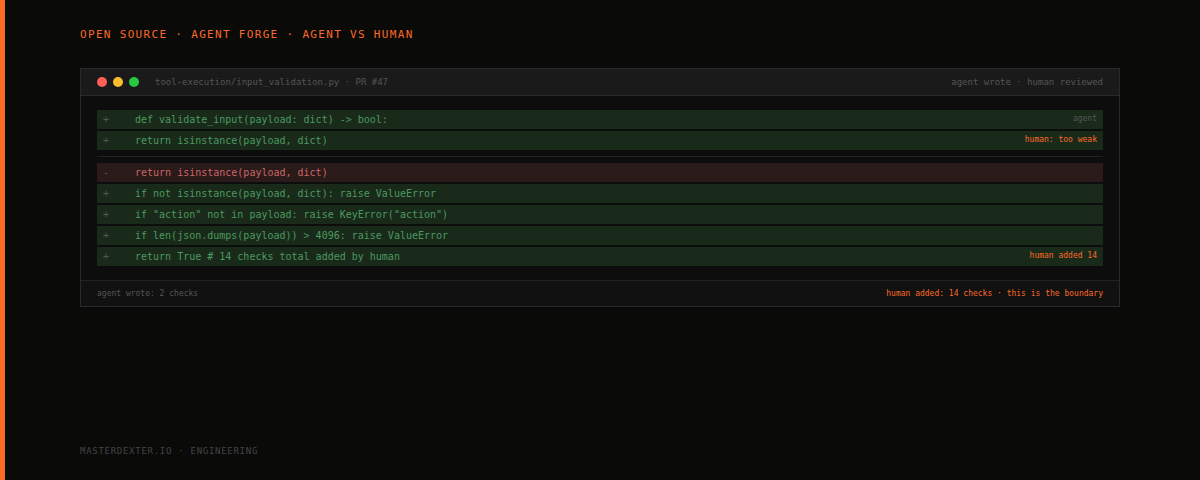
The agent's 2 checks: verify the payload is a dictionary, verify it is not empty.
The reviewer's 14: required field validation for action and context, maximum payload size enforcement, key allowlist filtering (stripping any fields not in the expected schema), string sanitization on every string value, and a check that the generated code does not contain the 8 dangerous patterns from governance.py before the code reaches the Docker executor.
Read the PR comment thread. The reviewer explains, line by line, why each of the 14 checks matters and what production failure it prevents. The comment on the payload size check is particularly good: without it, a user could submit a task containing a 50MB string and crash the container with an OOM error before any code was generated.
PR #47 is the most honest document about where LLM code generation is reliable and where human engineering judgment is irreplaceable that exists in a public repo. The agent wrote the scaffold. The human engineer wrote the production safety.
3. Echo Negotiator: Read the Async Task Cleanup Commit
Repo: github.com/MasterDexterAI/echo-negotiator
What to look at: Commit fix/async-task-cleanup in the websocket-handler branch.
This is the commit that fixed the memory leak found during adversarial testing. 12 lines changed. The fix is a finally block added to the interruption handler.
The interesting part is not the fix. It is the surrounding context the commit message provides: the developer explains why asyncio.CancelledError is a subclass of BaseException, not Exception, which means a bare except Exception: silently swallows the cancellation without executing the cleanup. The bug was invisible in testing because test environments do not run 90 consecutive interruptions.
async def handle_interruption(self):
if self.current_generation_task:
self.current_generation_task.cancel()
try:
await self.current_generation_task
except asyncio.CancelledError:
pass
finally:
self.current_generation_task = None # This line was missing
That finally block is the fix. Without it, the reference to the cancelled task persists. Python's garbage collector does not collect it because there is still a reference. Memory leaks one cancelled task at a time.
If you build anything with async Python and asyncio.CancelledError, this 12-line commit will save you hours.
4. Model Smith: Read the Synthetic Data Quality Filter
Repo: github.com/MasterDexterAI/model-smith
What to look at: /src/synthesis/data_cleaner.py
Model Smith generates 2,000 training examples using GPT-4 as a teacher model. Not all 2,000 are good. This file filters the bad ones before fine-tuning.
The filter has 5 rules:
- Minimum response length of 50 characters
- Maximum length of 2,000 characters
- Deduplication using a rolling hash against the last 200 examples
- Format validation: the SQL output must contain at least one SQL keyword from a defined list
- A secondary LLM check: if the output contains phrases like "I cannot" or "I am unable," the example is discarded
Rule 5 is the one worth studying. GPT-4 occasionally refuses a synthetic training task and returns a refusal instead of an example. Without this filter, you train on refusals. Your fine-tuned model learns to refuse tasks it should answer.
The function is 40 lines. It is the difference between a 1,600-example high-quality training set and a 2,000-example set where 20% of the examples actively harm the model's behavior.
5. Nexus Flow: Read the AI vs Human Collaboration Log
Repo: github.com/MasterDexterAI/nexus-flow
What to look at: /docs/agent-human-log.md
This file does not exist in most codebases. The cohort created it during week 4 after a pattern became clear across multiple artifact builds: there were specific categories of code the agents wrote well consistently, and specific categories where human review almost always changed the output significantly.
The log documents this across 6 weeks. Every time a cohort member accepted, modified, or rejected significant agent output, they logged it with a one-line reason.
The pattern across all artifacts: agent output for scaffolding, data models, test fixtures, and boilerplate was accepted unchanged at a high rate. Agent output for error handling, input validation, edge case coverage, and async cleanup logic was modified or rejected more than 60% of the time.
That pattern is the most useful thing a new AI engineer can learn. It tells you where to trust your agent and where to review carefully. No amount of reading about AI-assisted development teaches this as directly as this log does.
If you only read one thing from this list, read this one.
If your company needs a team trained on production AI engineering, the enterprise playbook and team programs are at AI Leadership Founding Cohort.