In Cohort 1, builders who completed the PILOT spec before writing code shipped in 8 days on average. Builders who skipped it took 17.
The spec is not documentation. It is not planning. It is the decisions you make in text, before making them in code, where they are cheap to change.
The DevFix spec went through one revision. The first version would have produced a chatbot that suggests code fixes. The second version produced a self-healing agent that runs them.
Here is both versions, with annotations on what changed and why.
Version 1: What Most Engineers Write
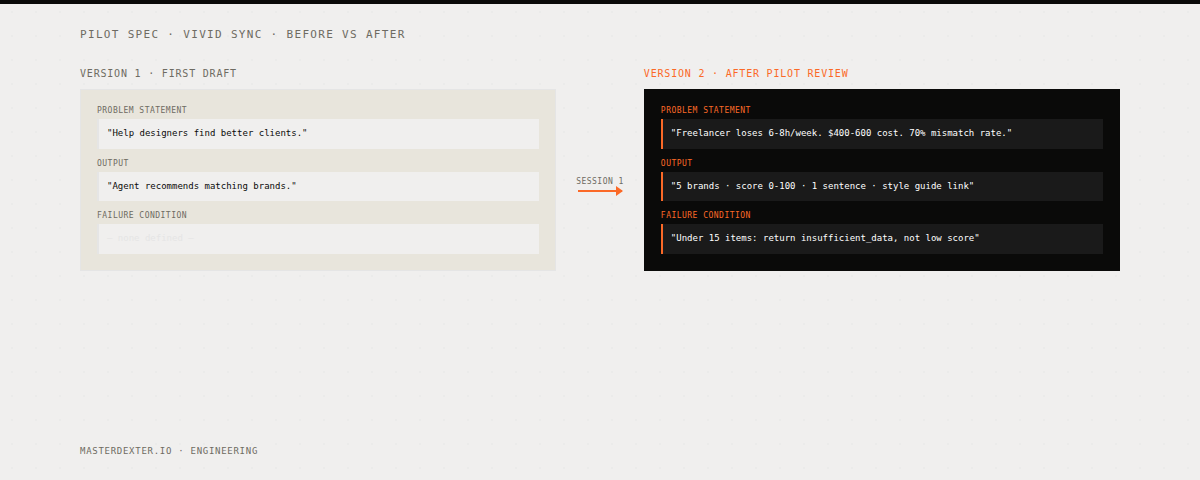
The spec the DevFix lead submitted before the first session:
Problem: Developers waste time debugging AI-generated code.
User: Software engineers.
What the agent does: Takes broken code and fixes it.
Output: Fixed code.
Success: The code works.
This spec is not wrong. But it is not a spec. It is a description of a vague idea. Every sentence is true and none of them are actionable.
An agent built to this spec would not know what "fixes it" means. Does it suggest a fix? Run the fix? Test the fix? Run it again if the test fails? How many times? Who decides when to stop?
These decisions end up in the code, made under pressure during a build session, often wrong.
Version 2: After One PILOT Problem Session
Problem: A software engineer using Copilot, Claude Code, or ChatGPT receives AI-generated code that fails immediately. She copies the error, pastes it back to the AI, pastes the new code into her editor, runs it, gets another error, and repeats. This loop takes 20 to 40 minutes per task on average for code that should take 5. The loop is manual because no tool closes it automatically.
User: A developer who regularly uses LLM tools to generate first-draft code and spends a significant portion of their day in manual debugging loops after generation.
Agent Input: A natural language task description. Example: "Write a function that merges two sorted lists and test it with PyTest."
Agent Output Schema:
{
"success": bool,
"final_code": str, // The passing code
"attempts": int, // How many iterations it took
"errors_encountered": list, // Each error message, in order
"latency_seconds": float // Total wall time
}
Success Condition: success == True AND all PyTest functions in final_code pass when executed independently. Pass rate across 50 benchmark tasks must exceed 80% on first attempt.
Failure Conditions:
- If
attemptsreaches 5 withoutsuccess, return the last generated code withsuccess: Falseand a clear failure message. Do not loop indefinitely. - If the task contains a request to access the filesystem, network, or system commands, return a safety block immediately.
- If PyTest is not present in the generated code, return an error before Docker execution.
Out of Scope (explicit):
- Multi-file projects
- Code that requires external dependencies not available in Python standard library
- Tasks requiring database connections
- Debugging existing user-owned code (input must be a task description, not existing code)
What Changed and Why
The problem statement got a person and a cost
Version 1: "Developers waste time debugging AI-generated code."
Version 2: "A software engineer... this loop takes 20 to 40 minutes per task on average for code that should take 5."
The revision has a person. It has a time cost. The agent can now be grounded in something real. When you evaluate whether the agent is working, you can measure against the 20-40 minute baseline. Without the baseline, "it works" is the only criterion. With it, you have something to actually measure.
The output became a schema
Version 1: "Fixed code."
Version 2: A JSON schema with 5 typed fields.
Every field in the schema maps to something testable. success is a boolean - testable in one line. attempts is an integer - testable. errors_encountered is a list - you can write assertions about its length and content.
"Fixed code" cannot be tested automatically. A schema can.
The schema also forced a decision that version 1 skipped: what does the agent return when it fails? This is the most important question in any agent design. The answer shapes the entire state management architecture.
Failure conditions were added
Version 1 had none.
Agents without explicit failure conditions hallucinate when they should refuse. An agent asked to write a function that connects to an external API, with no scope boundary defined, will attempt it. It will fail. It will loop. It will hit the attempt limit. The developer will wonder why.
The DevFix spec defines 3 failure conditions. Each one is a decision the developer would otherwise make at 11pm during a debugging session. Making it in the spec at 9am is better.
Out of Scope was explicit
Version 1 had no out-of-scope section.
The out-of-scope section is underrated. An agent with no defined boundaries expands into adjacent tasks it was not designed for. DevFix receives tasks. Without a boundary, a user might submit existing broken code expecting DevFix to fix it. The current architecture does not support that - it generates code for a task, it does not repair existing code. That is a different product.
Defining what the agent does not do forces a product decision into the open before it becomes a production incident.
The Spec Template Every Cohort Member Uses
## Problem Statement
[Specific person. Specific situation. Quantified cost in time, money, or risk.]
## Target User
[One person. One job title. One specific constraint they operate under.]
## Agent Input
[Exact format: what the user provides, in what form, with what constraints]
## Agent Output Schema
[JSON or structured format with field names, types, and what each one means]
## Success Condition
[Measurable. Testable. Not "it works."]
## Failure Conditions
[What the agent returns when it cannot succeed. At least 3 defined cases.]
## Out of Scope
[What this agent explicitly does not attempt to do]
The "Out of Scope" section is the one most people skip. It is also the one that saves the most debugging time.
Cohort 1 Numbers
Builders who submitted a completed spec before the first build session: 31 of 47.
Average days from spec completion to live URL for those 31: 8 days.
Average days for the 16 who either skipped the spec or submitted it after starting to build: 17 days.
The 9-day gap is not because writing the spec takes less time than coding. Writing a complete spec takes 2 to 4 hours. The gap comes from the decisions the spec makes before you write code. Builders who had those decisions made before session 1 spent their build time building. Builders who did not spent their build time deciding.
If your company needs a team trained on production AI engineering, the enterprise playbook and team programs are at AI Leadership Founding Cohort.