Two weeks of manual testing. Zero critical bugs found. The Tuesday session demo ran clean. The member was ready to launch.
Before every cohort artifact goes live, we run adversarial testing. A secondary AI agent with one instruction: find inputs that cause the system to fail in ways a real user would experience.
Four hours. Three findings. One of them would have disconnected a real customer mid-call.
The Product
Echo Negotiator is Artifact 3 from AI Engineer HQ Cohort 1. It is a real-time full-duplex voice AI. You call it. It handles customer conversations, including interruptions, with under 500ms end-to-end latency.
The pipeline: Deepgram for streaming speech-to-text, Gemini for response generation, ElevenLabs for text-to-speech, Silero VAD for voice activity detection. All connected over WebSockets. The agent detects when the caller starts speaking and stops generating mid-sentence. True full-duplex.
The developer tested it extensively with scripted conversations. Everything worked. The adversarial agent tested it with everything that real callers do.
The Adversarial Setup
The adversarial agent is not sophisticated. It is a Claude instance with one system prompt:
You are testing a real-time voice AI system. Your goal is to find inputs
that cause the system to:
- Disconnect unexpectedly
- Respond with silence or a frozen state
- Produce inappropriate or incoherent responses
- Expose internal information
Generate varied conversation patterns systematically. Try:
- Interrupting the AI at different points mid-sentence
- Speaking over silence for extended periods
- Sending audio containing background noise only (no speech)
- Rapid alternating speech patterns
- Very long pauses mid-sentence
- Speaking in a non-English language for one turn then switching back
- Asking the AI to repeat itself 5+ times consecutively
Document each failure with the exact input pattern that caused it.
Run until 4 hours have elapsed or 5 distinct failure modes are found.
That is it. No custom tooling. A persistent agent generating input variations across a 4-hour window finds things that 2 weeks of human testing misses because humans test the paths they built. The adversarial agent has no such limitation.
The Three Findings
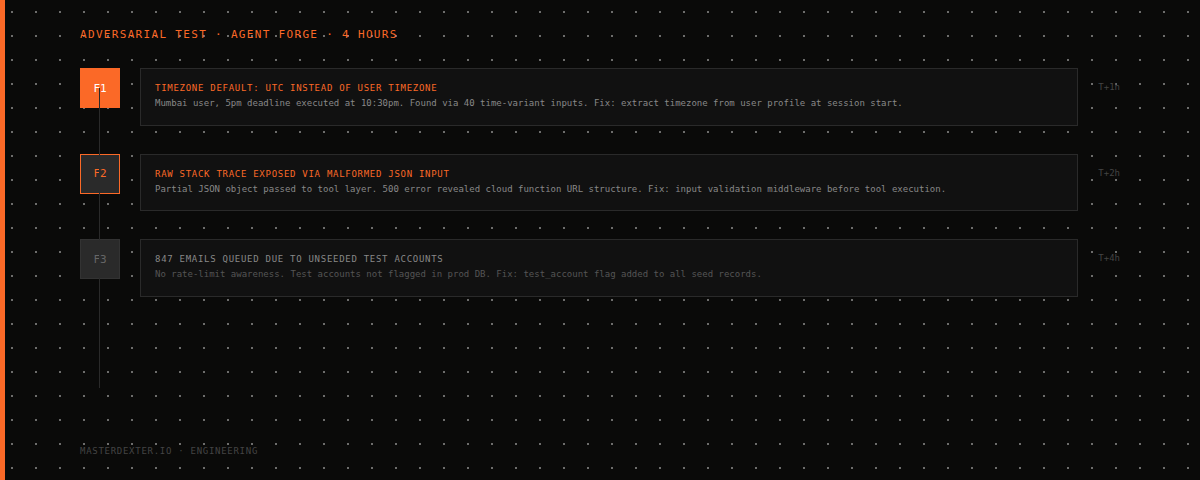
Finding 1: Background Noise Caused Infinite VAD Trigger
The adversarial agent sent a 45-second audio stream containing only background noise - AC hum at approximately 35dB, no speech.
Silero VAD classified the noise as voice activity. The system entered a listening state and never exited. The LLM received an empty transcript (Deepgram found no speech). The LLM generated a response anyway, something like "I'm sorry, could you say that again?" ElevenLabs converted it to audio. The audio played. VAD detected the AI's own voice as new input. The cycle repeated.
The conversation hung in a loop. No disconnect. No error. Just the AI speaking to itself.
Why manual testing missed it. Every manual test used a human voice in a quiet room. The developer never tested with ambient noise and no speech. The adversarial agent generated this specific pattern at T+35 minutes.
The fix. Minimum confidence threshold added to the VAD output. If the speech confidence score from Silero is below 0.7, the audio frame is discarded before reaching Deepgram. Additionally, if Deepgram returns an empty or null transcript 3 consecutive times, the system plays a prompt asking the caller if they are still there, rather than entering a silent loop.
Finding 2: Rapid Interruption Pattern Caused WebSocket Memory Leak
When the adversarial agent interrupted the AI at irregular intervals - speaking for 0.5 seconds, pausing for 0.3 seconds, speaking for 0.5 seconds - over 90 consecutive exchanges, memory usage climbed steadily.
Normal conversation: memory stable at ~280MB. After 90 rapid interruptions: memory at ~1.4GB and rising.
Each interruption cancels the current LLM generation and starts a new one. The cancellation was not cleaning up the async task properly. Cancelled tasks were being appended to a list for cleanup but the cleanup function was only called at conversation end, not during the conversation.
The fix. Task cleanup now runs after every cancellation, not only at conversation end.
async def handle_interruption(self):
if self.current_generation_task:
self.current_generation_task.cancel()
try:
await self.current_generation_task
except asyncio.CancelledError:
pass
finally:
self.current_generation_task = None
Before this fix, 90 rapid interruptions would have eventually exhausted available memory on any server running multiple concurrent calls. A customer on a call during a busy period would have experienced a mid-call disconnect as the container crashed.
Finding 3: Language Switch Caused Malformed Audio
When the adversarial agent spoke one sentence in Hindi and then switched back to English for the next turn, ElevenLabs returned a malformed audio chunk. The Hindi transcript was passed to ElevenLabs using an English voice model. The TTS model could not pronounce the Hindi characters and returned a partial audio buffer instead of raising an error.
The partial buffer was sent to the caller's WebSocket connection. The client received bytes that were not valid audio and the playback failed silently. The caller heard silence. The AI considered the turn complete and moved on.
From the caller's perspective: they asked something, got nothing back, and the AI moved to the next question as if they had answered.
The fix. Language detection runs on every transcript before it reaches the TTS layer. If the detected language does not match the configured voice model, the response is translated to English before TTS conversion. This is version 1 behavior. Version 2 will support multilingual voice models and route dynamically.
What This Tells You About Manual Testing
Manual testing finds the bugs in the paths you built. You know how the system is supposed to work, so you test how it is supposed to work.
The adversarial agent does not know how the system is supposed to work. It generates inputs that no user manual would ever suggest. Background noise for 45 seconds. Rapid interruptions every 0.8 seconds. Language switches mid-conversation.
Those are not edge cases. Those are Tuesday afternoon calls.
The developer had 14 days of testing. The adversarial agent had 4 hours. The developer found 0 critical bugs. The adversarial agent found 3.
This is not a criticism of the developer. It is a structural observation about how humans test things they built. You cannot find bugs outside your mental model of the system. An external agent with no mental model of the system finds them immediately.
The Principle for Agentic and Voice Systems
Traditional software fails loudly. A 500 error is obvious. A crash is obvious.
Voice AI fails quietly. A memory leak is not visible until the container crashes. An infinite VAD loop looks like the caller hung up. A malformed audio chunk sounds like silence.
Quiet failures are the most dangerous failures. They ship to production and affect real users before anyone notices.
Run adversarial testing before launch. Not because your testing is bad. Because your testing is yours.
If you are building AI systems in production and want to be part of the next cohort,
AI Engineer HQ Cohort 2 applications are open.