BLEU scores were invented for machine translation in 2002. They measure n-gram overlap between your output and a reference answer.
They do not work for LLM outputs. A model that generates "the query returns all rows where status equals active" is correct. A BLEU comparison against a reference that says "SELECT * FROM orders WHERE status = 'active'" gives a low score. Different words. Same answer.
Karpathy said evals are one of the most scarce skills in AI engineering right now. He is right. Most builders do not have an eval problem. They have a rubric problem. They write criteria like "accurate" and "helpful" and wonder why their LLM-as-judge scores are useless.
This is the 3-layer eval system running across all 6 artifacts in AI Engineer HQ Cohort 1. It works for systems with no single right answer. Model Smith, the synthetic data generation and fine-tuning artifact, is the hardest case. We use it as the primary example here.
What Model Smith Does (And Why Evaluation Is Hard)
Model Smith is Artifact 4. It takes a high-cost general task (SQL generation, email drafting, data extraction) and builds a fine-tuned 8B model that does that specific task at GPT-4 quality for a fraction of the inference cost.
The pipeline: use GPT-4 to generate 2,000 synthetic training examples, filter for quality, fine-tune Llama-3.2-8B with QLoRA on a rented GPU, evaluate the result.
The evaluation question: is the fine-tuned model actually better? And "better" has three dimensions: factual correctness, stylistic match to what users want, and edge case handling. None of these have a canonical ground truth.
You cannot BLEU-score SQL correctness. You can run the query. But running every generated query against a live database is not practical at eval scale. You need something in between.
The 3-layer system is that something.
The 3-Layer Eval System
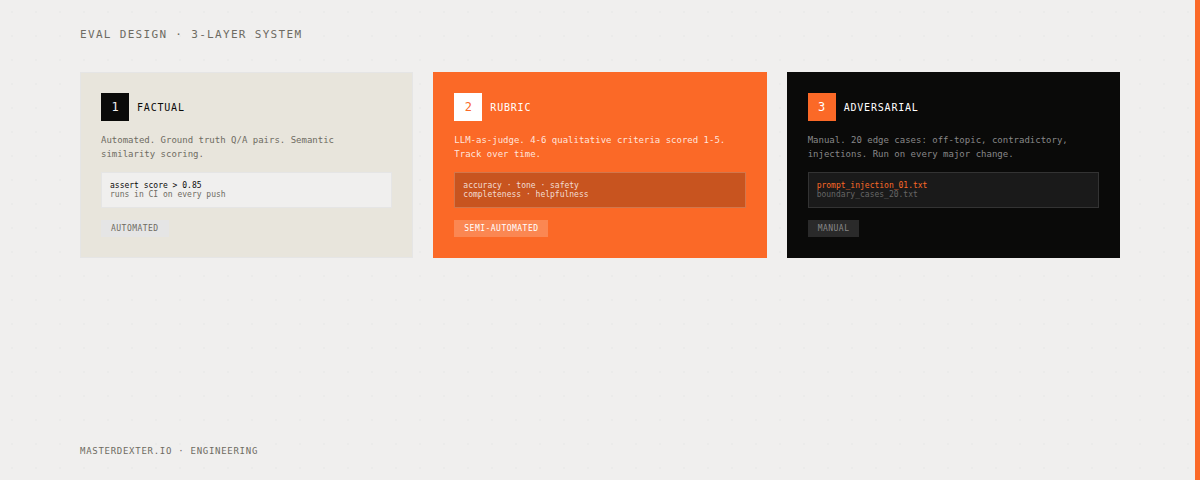
Layer 1: Factual Correctness - Automated
This layer catches regressions. It tells you when your last change broke something that was working.
Write 50 ground truth examples specific to your domain. Not generic. Specific to the exact task your system handles.
For Model Smith evaluating SQL generation, this means 50 tasks with a reference SQL query the team verified as correct:
{
"task": "Get all orders placed in the last 30 days with status 'pending'",
"reference": "SELECT * FROM orders WHERE status = 'pending' AND created_at >= NOW() - INTERVAL '30 days'",
"category": "date_filter"
}
Score each model output using semantic similarity against the reference. all-MiniLM-L6-v2 works fine for this. It is fast, local, and accurate enough for factual regression detection.
from sentence_transformers import SentenceTransformer, util
scorer = SentenceTransformer("all-MiniLM-L6-v2")
def score_output(output: str, reference: str) -> float:
emb_output = scorer.encode(output, convert_to_tensor=True)
emb_ref = scorer.encode(reference, convert_to_tensor=True)
return float(util.cos_sim(emb_output, emb_ref))
def run_layer_1(test_cases: list) -> dict:
scores = []
failures = []
for case in test_cases:
score = score_output(case["model_output"], case["reference"])
scores.append(score)
if score < 0.85:
failures.append({**case, "score": round(score, 3)})
return {
"pass_rate": round(sum(1 for s in scores if s >= 0.85) / len(scores), 3),
"mean_score": round(sum(scores) / len(scores), 3),
"failures": failures
}
Set a threshold. We use 0.85 cosine similarity as the minimum pass score. This runs in CI on every commit. If pass rate drops below baseline, the deployment blocks.
Start with 10 cases if you have nothing. It is better than zero. Add 5 more every week. By the end of a 6-week cohort, you have 40 covering the most common failure modes. That is when Layer 1 starts catching things you did not expect.
Layer 2: Rubric Scoring - Semi-Automated
This layer catches quality problems that factual correctness misses.
A SQL query can be syntactically correct and semantically wrong. An email draft can be factually accurate and tonally off. Layer 1 passes. The user is still unhappy.
Define 4 to 6 qualitative criteria. Then use a secondary LLM to score each output against your rubric. The trick is writing criteria specific enough that the judge model gives consistent scores.
This fails:
Criterion: Is the output helpful?
This works:
Criterion: Does the SQL query handle the exact date range specified in the task
without adding implicit filters or missing the stated condition?
Score 1 if it misses the date condition. Score 3 if it addresses it but adds
unnecessary filters. Score 5 if it handles it precisely as stated.
Here is the rubric we use for Model Smith SQL evaluation:
| Criterion | Definition | Weight |
|---|---|---|
| Correctness | Does the query return the right data for the stated task? | 1.5x |
| Syntax | Would this execute without errors in PostgreSQL? | 1.0x |
| Completeness | Does it handle all conditions mentioned in the task? | 1.0x |
| Efficiency | Does it avoid unnecessary subqueries or joins? | 0.7x |
| Edge case handling | Does it handle NULL values and empty sets? | 0.8x |
RUBRIC_PROMPT = """
You are evaluating a SQL query generated by an AI model.
Task: {task}
Generated query: {output}
Criterion: {criterion}
Definition: {definition}
Score this criterion from 1 to 5.
Return ONLY a single integer between 1 and 5. No explanation.
"""
def score_rubric_criterion(task, output, criterion, definition, judge_model) -> int:
prompt = RUBRIC_PROMPT.format(
task=task,
output=output,
criterion=criterion,
definition=definition
)
response = judge_model.invoke(prompt)
try:
return int(response.content.strip())
except:
return 3
Run this weekly on a sample of 200 real interactions. Track scores over time. A drop of more than 0.3 weighted points on any single criterion across a weekly batch signals something worth investigating. It might be a prompt change. It might be a new query type the system was not designed for.
Layer 3: Adversarial Testing - Manual
This layer finds failures that happen in real usage but do not appear in your standard test set.
Every release of Model Smith gets 20 edge case prompts designed to find the specific failure modes of fine-tuned SQL generation models:
- Tasks that require JOINs across 3+ tables (fine-tuned models often overfit to simpler queries)
- Tasks with ambiguous column names that exist in multiple tables
- Tasks with date arithmetic that the training data did not cover well
- Tasks asking for data that does not exist in the schema (the model should say so, not hallucinate a table)
- Prompt injection attempts embedded in the task description
Run these before every significant release. Document which pass and which fail. Failures go into the Layer 1 ground truth set after you fix them. That is how your eval suite grows into a real map of where your system breaks.
What a Real Eval Run Looks Like
For Model Smith, the weekly eval cycle:
- Layer 1 runs in GitHub Actions on every commit. Currently 40 test cases. Takes 90 seconds.
- Layer 2 runs manually on Sunday on 200 randomly sampled outputs from the week. Takes 12 minutes with Claude Haiku as judge. Scores reviewed in 5 minutes.
- Layer 3 runs before any release. 20 adversarial cases. Developer reviews every output.
Total time per week: 30 minutes. That is the price of knowing your model is not regressing.
The scores go into a dashboard. When the cohort member presents Model Smith at the Sunday session, they can show not just that it works but by how much. The fine-tuned Llama-3.2-8B scored 78% on Layer 1 before fine-tuning. After fine-tuning on 1,600 quality-filtered examples, it scored 91%. Layer 2 weighted rubric average moved from 3.2 to 4.1 out of 5.
Those numbers change how a hiring manager reads a portfolio. "I fine-tuned a model" is one thing. "I fine-tuned a model, measured the quality improvement across 40 ground truth cases and a 5-criterion rubric, and achieved a 13-point pass rate improvement" is another.
The Eval Template
Every cohort artifact ships with this config:
eval_config:
layer_1:
test_cases_path: "evals/ground_truth.jsonl"
similarity_threshold: 0.85
ci_blocking: true
minimum_cases: 30
layer_2:
sample_size: 200
judge_model: "claude-haiku-4-5"
rubric_path: "evals/rubric.yaml"
alert_threshold_points: 0.3
cadence: "weekly"
layer_3:
adversarial_path: "evals/adversarial/"
cadence: "pre-release"
reviewer: "developer"
The minimum_cases: 30 flag is new for Cohort 2. In Cohort 1, several members launched with 10 cases. The Layer 1 pass rate looked good at 90%. But 10 cases is not enough coverage to catch the failure modes that real users find in week 1. Cohort 2 requires 30 before launch approval.
The Rubric Mistake to Avoid
If you take one thing from this: write rubric criteria that are specific enough to have a wrong answer.
"Is this helpful?" cannot have a wrong answer. Every model says its output is helpful.
"Does this response address the user's specific question without adding unrequested advice or information?" can have a wrong answer. The judge model can evaluate it consistently. You can track it over time.
The specificity of your rubric determines whether your Layer 2 eval is signal or noise. Most teams are generating noise.
If you are building AI systems in production and want to be part of the next cohort,
AI Engineer HQ Cohort 2 applications are open.